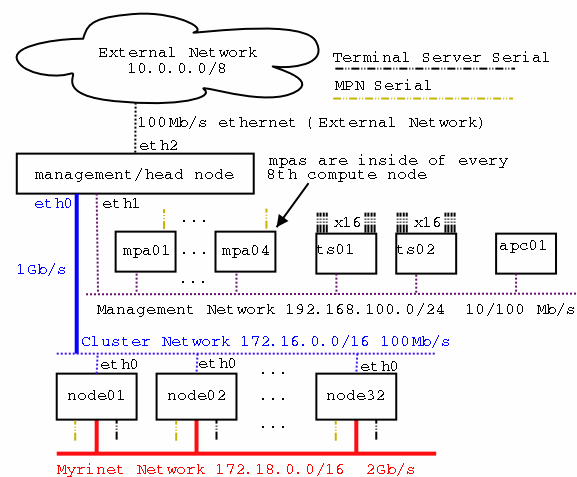
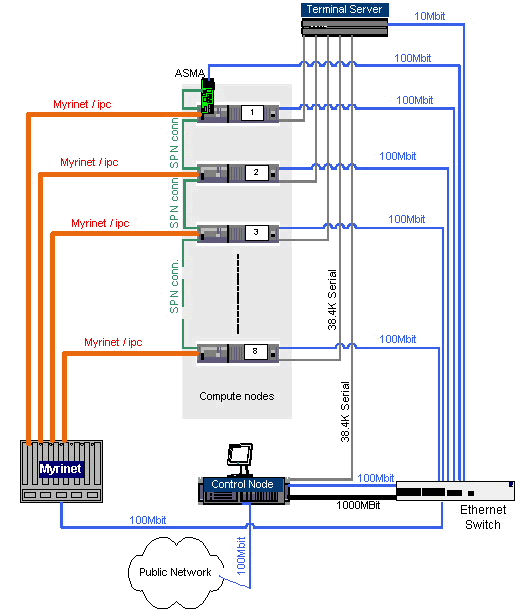
This section describes some of the xCAT configuration necessary
for the 32 node example cluster. If your cluster differs from this
example, you'll have to make changes. xCAT configuration files are
located in /usr/local/xcat/etc. You must setup these
configuration files before proceeding.
| 9.1 Copy the Sample Config Files to
Their Required
Location
| > mkdir
/usr/local/xcat/etc
> cp
/usr/local/xcat/samples/etc/* /usr/local/xcat/etc
| 9.2 Create Your Own Custom
Configuration
| Edit /usr/local/xcat/etc/* to
suit your cluster. Please read the man pages 'man site.tab',
etc., to learn more about the format of these configuration files.
There is a bit more detail on some of these files in some of the
later sections. The following are examples that will work with our
example 32 node cluster...
/usr/local/xcat/etc/site.tab
# site.tab control most of xCAT's global settings.
# man site.tab for information on what each field means.
rsh /usr/bin/ssh
rcp /usr/bin/scp
gkhfile /usr/local/xcat/etc/gkh
tftpdir /tftpboot
tftpxcatroot xcat
domain mydomain.com
nameservers 172.16.100.1
nets 172.16.0.0:255.255.0.0,172.17.0.0:255.255.0.0,172.18.0.0:255.255.0.0
dnsdir /var/named
dnsallowq 172.16.0.0:255.255.0.0,172.17.0.0:255.255.0.0,172.18.0.0:255.255.0.0
domainaliasip 172.16.100.1
mxhosts mydomain.com,man-c.mydomain.com
mailhosts man-c
master man-c
pbshome /var/spool/pbs
pbsprefix /usr/local/pbs
pbsserver man-c
scheduler maui
xcatprefix /usr/local/xcat
keyboard us
timezone US/Central
offutc -6
mapperhost NA
serialmac 0
snmpc public
timeservers man-c
logdays 7
installdir /install
clustername WOPR
dhcpver 2
dhcpconf /etc/dhcpd.conf
clusternet 172.16.0.0
dynamic 172.30.0.1,255.255.0.0,172.30.1.1,172.30.254.254
dynamictype ia32
usernodes man-c
usermaster man-c
nisdomain mydomain.com
nismaster man-c
nisslaves NA
homelinks NA
chagemin 0
chagemax 60
chagewarn 10
chageinactive 0
mpcliroot /usr/local/xcat/lib/mpcli
/usr/local/xcat/etc/nodelist.tab
# nodelist.tab contains a list of nodes and defines groups that
# can be used in commands. man nodelist.tab for more information.
node01 all,rack1,compute,myri,spn1
node02 all,rack1,compute,myri,spn1
node03 all,rack1,compute,myri,spn1
node04 all,rack1,compute,myri,spn1
node05 all,rack1,compute,myri,spn1
node06 all,rack1,compute,myri,spn1
node07 all,rack1,compute,myri,spn1
node08 all,rack1,compute,myri,spn1
node09 all,rack1,compute,myri,spn2
node10 all,rack1,compute,myri,spn2
node11 all,rack1,compute,myri,spn2
node12 all,rack1,compute,myri,spn2
node13 all,rack1,compute,myri,spn2
node14 all,rack1,compute,myri,spn2
node15 all,rack1,compute,myri,spn2
node16 all,rack1,compute,myri,spn2
node17 all,rack1,compute,myri,spn3
node18 all,rack1,compute,myri,spn3
node19 all,rack1,compute,myri,spn3
node20 all,rack1,compute,myri,spn3
node21 all,rack1,compute,myri,spn3
node22 all,rack1,compute,myri,spn3
node23 all,rack1,compute,myri,spn3
node24 all,rack1,compute,myri,spn3
node25 all,rack1,compute,myri,spn4
node26 all,rack1,compute,myri,spn4
node27 all,rack1,compute,myri,spn4
node28 all,rack1,compute,myri,spn4
node29 all,rack1,compute,myri,spn4
node30 all,rack1,compute,myri,spn4
node31 all,rack1,compute,myri,spn4
node32 all,rack1,compute,myri,spn4
asma1 asma
asma2 asma
asma3 asma
asma4 asma
ts1 ts
ts2 ts
/usr/local/xcat/etc/mpa.tab
# mpa.tab defines what type of service processor adapters
# the cluster has and how to use their functionality.
# Our example cluster uses only ASMAs with telnet and http.
# man mpa.tab for more information
#
#service processor adapter management
#
#type = asma,rsa
#name = internal name (must be unique)
# internal name should = node name
# if rsa/asma is primary management
# processor
#number = internal number (must be unique and > 10000)
#command = telnet,mpcli
#reset = http(ASMA only),mpcli,NA
#
#mpa type,name,number,command,reset,rvid
asma1 asma,asma1,10001,telnet,http,telnet
asma2 asma,asma2,10002,telnet,http,telnet
asma3 asma,asma3,10003,telnet,http,telnet
asma4 asma,asma4,10004,telnet,http,telnet
/usr/local/xcat/etc/mp.tab
# mp.tab defines how the Service processor network is setup.
# node07 is accessed via the name 'node07' on the ASMA 'asma1', etc.
# man asma.tab for more information until the man page to mp.tab is ready
node01 asma1,node01
node02 asma1,node02
node03 asma1,node03
node04 asma1,node04
node05 asma1,node05
node06 asma1,node06
node07 asma1,node07
node08 asma1,node08
node09 asma2,node09
node10 asma2,node10
node11 asma2,node11
node12 asma2,node12
node13 asma2,node13
node14 asma2,node14
node15 asma2,node15
node16 asma2,node16
node17 asma3,node17
node18 asma3,node18
node19 asma3,node19
node20 asma3,node20
node21 asma3,node21
node22 asma3,node22
node23 asma3,node23
node24 asma3,node24
node25 asma4,node25
node26 asma4,node26
node27 asma4,node27
node28 asma4,node28
node29 asma4,node29
node30 asma4,node30
node31 asma4,node31
node32 asma4,node32
/usr/local/xcat/etc/apc.tab
# apc.tab defines the relationship between nodes and APC
# MasterSwitches and their assigned outlets. In our example,
# the power for asma1 is plugged into the 1st outlet the the
# APC MasterSwitch, etc.
asma1 apc1,1
asma2 apc1,2
asma3 apc1,3
asma4 apc1,4
ts1 apc1,5
ts2 apc1,6
/usr/local/xcat/etc/conserver.cf
# conserver.cf defines how serial consoles are accessed. Our example
# uses the ELS terminal servers and node01 is connected to port 1
# on ts1, node02 is connected to port 2 on ts1, node17 is connected to
# port 1 on ts2, etc.
# man conserver.cf for more information
#
# The character '&' in logfile names are substituted with the console
# name. Any logfile name that doesn't begin with a '/' has LOGDIR
# prepended to it. So, most consoles will just have a '&' as the logfile
# name which causes /var/consoles/ to be used.
#
LOGDIR=/var/log/consoles
#
# list of consoles we serve
# name : tty[@host] : baud[parity] : logfile : mark-interval[m|h|d]
# name : !host : port : logfile : mark-interval[m|h|d]
# name : |command : : logfile : mark-interval[m|h|d]
#
node01:!ts1:3001:&:
node02:!ts1:3002:&:
node03:!ts1:3003:&:
node04:!ts1:3004:&:
node05:!ts1:3005:&:
node06:!ts1:3006:&:
node07:!ts1:3007:&:
node08:!ts1:3008:&:
node09:!ts1:3009:&:
node10:!ts1:3010:&:
node11:!ts1:3011:&:
node12:!ts1:3012:&:
node13:!ts1:3013:&:
node14:!ts1:3014:&:
node15:!ts1:3015:&:
node16:!ts1:3016:&:
node17:!ts2:3001:&:
node18:!ts2:3002:&:
node19:!ts2:3003:&:
node20:!ts2:3004:&:
node21:!ts2:3005:&:
node22:!ts2:3006:&:
node23:!ts2:3007:&:
node24:!ts2:3008:&:
node25:!ts2:3009:&:
node26:!ts2:3010:&:
node27:!ts2:3011:&:
node28:!ts2:3012:&:
node29:!ts2:3013:&:
node30:!ts2:3014:&:
node31:!ts2:3015:&:
node32:!ts2:3016:&:
%%
#
# list of clients we allow
# {trusted|allowed|rejected} : machines
#
trusted: 127.0.0.1
/usr/local/xcat/etc/conserver.tab
# conserver.tab defines the relationship between nodes and
# conserver servers. Our example uses only one conserver on
# the localhost. man conserver.tab for more information.
node01 localhost,node01
node02 localhost,node02
node03 localhost,node03
node04 localhost,node04
node05 localhost,node05
node06 localhost,node06
node07 localhost,node07
node08 localhost,node08
node09 localhost,node09
node10 localhost,node10
node11 localhost,node11
node12 localhost,node12
node13 localhost,node13
node14 localhost,node14
node15 localhost,node15
node16 localhost,node16
node17 localhost,node17
node18 localhost,node18
node19 localhost,node19
node20 localhost,node20
node21 localhost,node21
node22 localhost,node22
node23 localhost,node23
node24 localhost,node24
node25 localhost,node25
node26 localhost,node26
node27 localhost,node27
node28 localhost,node28
node29 localhost,node29
node30 localhost,node30
node31 localhost,node31
node32 localhost,node32
/usr/local/xcat/etc/nodehm.tab
# nodehm.tab defines the relationship between nodes and
# hardware management methods. man nodehm.tab for more info.
#
#node hardware management
#
#power = mp,apc,apcp,NA
#reset = mp,apc,apcp,NA
#cad = mp,NA
#vitals = mp,NA
#inv = mp,NA
#cons = conserver,tty,rtel,NA
#bioscons = mp,NA
#eventlogs = mp,NA
#getmacs = rcons,cisco3500
#netboot = pxe,eb,ks62,elilo,NA
#eth0 = eepro100,pcnet32,e100
#gcons = vnc,NA
#
#node power,reset,cad,vitals,inv,cons,bioscons,eventlogs,getmacs,netboot,eth0,gcons
#
node01 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node02 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node03 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node04 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node05 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node06 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node07 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node08 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node09 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node10 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node11 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node12 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node13 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node14 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node15 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node16 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node17 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node18 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node19 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node20 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node21 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node22 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node23 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node24 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node25 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node26 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node27 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node28 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node29 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node30 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node31 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
node32 mp,mp,mp,mp,mp,conserver,mp,mp,rcons,pxe,eepro100,vnc
asma1 apc,apc,NA,NA,NA,NA,NA,NA,NA,NA,NA,NA
asma2 apc,apc,NA,NA,NA,NA,NA,NA,NA,NA,NA,NA
asma3 apc,apc,NA,NA,NA,NA,NA,NA,NA,NA,NA,NA
asma4 apc,apc,NA,NA,NA,NA,NA,NA,NA,NA,NA,NA
ts1 apc,apc,NA,NA,NA,NA,NA,NA,NA,NA,NA,NA
ts2 apc,apc,NA,NA,NA,NA,NA,NA,NA,NA,NA,NA
/usr/local/xcat/etc/noderes.tab
# noderes.tab defines the resources for each node.
# If you're cluster doesn't use GM, PBS, or you want users to be
# able to access compute nodes even if they aren't running a job
# on them, you'll need to modify the GM, PBS, and ACCESS fields.
# For changes to this file to take effect, you must do a 'mkks',
# 'nodeset' and reinstall the node.
# man noderes.tab for more information.
#
#TFTP = Where is my TFTP server?
# Used by makedhcp to setup /etc/dhcpd.conf
# Used by mkks to setup update flag location
#NFS_INSTALL = Where do I get my files?
#INSTALL_DIR = From what directory?
#SERIAL = Serial console port (0, 1, or NA)
#USENIS = Use NIS to authencate (Y or N)
#INSTALL_ROLL = Am I also an installation server? (Y or N)
#ACCT = Turn on BSD accounting
#GM = Load GM module (Y or N)
#PBS = Enable PBS (Y or N)
#ACCESS = access.conf support
#INSTALL NIC = eth0, eth1, ... or NA
#
#node/group TFTP,NFS_INSTALL,INSTALL_DIR,SERIAL,USENIS,INSTALL_ROLL,\
# ACCT,GM,PBS,ACCESS,INSTALL_NIC
#
# the entries below can be accomplished with a single line...
# all man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node01 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node02 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node03 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node04 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node05 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node06 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node07 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node08 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node09 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node10 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node11 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node12 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node13 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node14 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node15 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node16 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node17 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node18 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node19 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node20 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node21 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node22 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node23 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node24 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node25 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node26 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node27 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node28 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node29 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node30 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node31 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
node32 man-c,man-c,/install,0,Y,N,N,Y,Y,Y,NA
/usr/local/xcat/etc/nodetype.tab
# nodetype.tab maps nodes to types of installs.
# Our example uses only one type, but you might have a few
# different types.. a subset of nodes with GigE, storage nodes,
# etc. man nodetype.tab for more information.
node01 compute71
node02 compute71
node03 compute71
node04 compute71
node05 compute71
node06 compute71
node07 compute71
node08 compute71
node09 compute71
node10 compute71
node11 compute71
node12 compute71
node13 compute71
node14 compute71
node15 compute71
node16 compute71
node17 compute71
node18 compute71
node19 compute71
node20 compute71
node21 compute71
node22 compute71
node23 compute71
node24 compute71
node25 compute71
node26 compute71
node27 compute71
node28 compute71
node29 compute71
node30 compute71
node31 compute71
node32 compute71
/usr/local/xcat/etc/passwd.tab
# passwd.tab defines some passwords that will be used in the cluster
# man passwd.tab for more information.
cisco cisco
rootpw netfinity
asmauser USERID
asmapass PASSW0RD
|